Main Menu
Introduction
Supercomputer Timeline
How does it work?
Types of Supercomputers
What are Supercomputers used for?
Conclusion
Works Cited
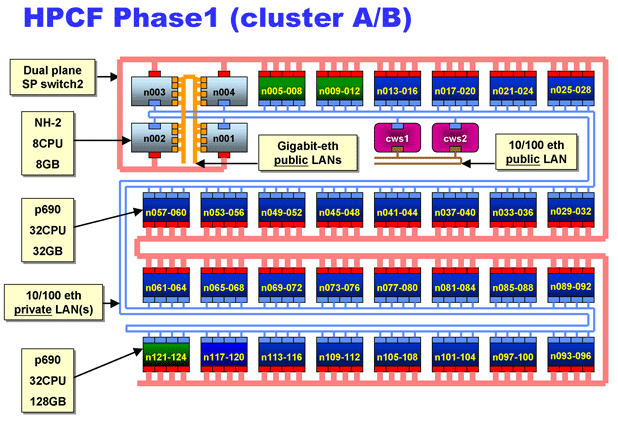
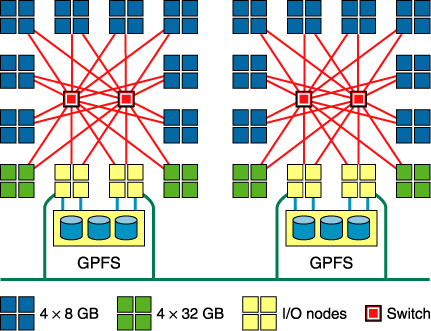
How does it work?
There are two major parts to a supercomputer, and they are the central processing unit, also known as the CPU, and the memory. The role of the CPU is to carry out instructions and the memory is where the instructions and data are stored. Also, a supercomputer has transistor technology which minimizes “transistor switching time.” Transistor switching time is, “the length of time that it takes for a transistor in the CPU to open or close, which corresponds to a piece of data moving or changing value in the computer.” Those engineers who design supercomputers use high performance circuits and architectures to make CPU’s that are 10 to 20 times faster than the top of the line CPU’s used for other commercial computers. A supercomputer’s memory functions like that of a regular computer, the only difference is that supercomputers can get to the memory a lot faster. A supercomputer also works like a regular computer; the difference is that it can do calculations much faster. The engineers who make supercomputers use two main ways to reduce the time it spends executing instructions; pipelining and parallelism. Pipelining allows multiple operations to take place at the same time in the supercomputer’s CPU by grouping together pieces of information that need to have the same sequence of operations performed on them, and then feed them through the CPU one after another. In pipelining, logic circuits used on a certain calculations are continuously being used, with information flowing from one logic unit to another without interruption. The way pipelining works, for example, would be it performs step 1 and moves the pair of information to step 2. Then, because the first pair of information has moved to step 2, the second pair of information can move to step 1. Next, step 1 and 2 are performed at the same time on their own respective information; and their results move ahead in the pipeline. Hitherto, the third pair of information is in step 1, the second pair of information is in step 2 and the first pair of information is in step 3. This sequence continues until the information is completely processed. However, in parallel processing the computer would perform step 1 on many pieces of information at the same time, then move that information on to step 2 and then 3. Pipelining and parallelism are very important in the processing of supercomputers and it is what helps them to perform at such high speeds. Parallelism and pipelining are combined and used in some way in all supercomputers.(Encarta)