
|




|
|
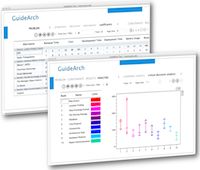
GuideArch
|
In early design, the engineer is often forced to make decisions without realizing the precise impact of those decisions on the various quality attributes. GuideArch is a framework aimed at quantitative exploration of the architectural solution space under uncertainty. It provides techniques founded on fuzzy mathematics that help the engineer with making informed decisions to increase the quality of the software. GuideArch provides a combination of capabilities, such as ranking the architectures and identifying the critical decisions, that collectively help with the exploration of the solution space. As a software project progresses, the architectural models become more concrete and enriched with information collected from simulations and prototypes, subsequently increasing the accuracy with which decisions can be made. GuideArch lends itself to an iterative approach and uses additional information to increase the accuracy of its quantitative reasoning.
Main Publication
|
|
|
|
|
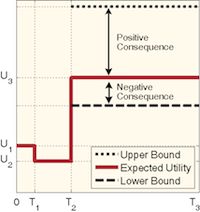
POISED
|
Autonomous software systems regularly need to make decisions to maintain their quality. These decisions, however, are prone to uncertainty. Uncertainty challenges the confidence with which the adaptation decisions are made. There are two specific sources of uncertainty at run-time: (1) variations in monitored system parameters due to either noise or actual change of parameters, and (2) inaccuracy of analytical models due to their simplifying assumptions. POISED uses possibility theory to assess both the negative and positive consequences of uncertainty and makes adaptation decisions that result in the best range of potential behavior.
Main Publication
|
|
|
|
|
FUSION
|
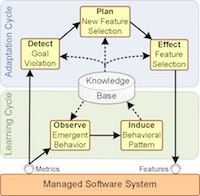
The effects of adaptation decisions on quality attributes are usually expressed by analytical models. Analytical models for different quality attributes do not share common characteristics and should be developed independently. Considering the complexity of today's software systems, this task is very difficult. Moreover, autonomous software systems usually run for a long period of time and this increases the chance of invalidating the assumptions that are used for developing the models at design-time. FUSION is a solution to this problem, where the concept of feature is borrowed from the product lines and used at run-time. FUSION uses machine learning to derive the effect of enabling/disabling features on quality attributes and uses this knowledge during adaptation for various purposes.
Main Publication
|
|
|
|
|
SASSY
|
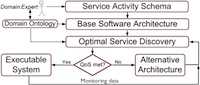
In service-oriented software systems the desired functionality is usually provided by dynamically discovering and binding to services. Therefore, the quality of software highly depends on the services that are used by the system. SASSY helps these systems to maintain their quality of service objectives at run-time. If one of the quality attributes of a system (such as response time or reliability) fails to conform to the objectives and services with better quality are not available, architectural level remedies will be used to bring the system back on track. To that end, an optimal architecture is automatically generated with the aid of design patterns.
Main Publication
|
|
|
|
|
Adaptation Patterns
|
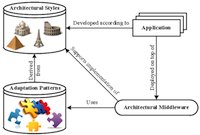
It is important to maintain the consistency of the system during the execution of changes enforced by autonomous software systems at run-time. Existing solutions to this problem either cause a lot of disruption in the system or require internal knowledge about the system's components and their dependencies, which may or may not be available. I used the implicit knowledge in the architectural style of a software system to decrease disruption without requiring such knowledge. I formalized the knowledge of different architectural styles as a repository of reusable adaptation patterns and implemented them on top of Prism-MW, which is an architectural middleware for embedded and mobile platforms. Prism-MW uses these patterns to safely adapt any given system, which is built according to a known style, without requiring internal knowledge about that system.
Main Publication
|
|
|
|
|
Mining Execution History
|
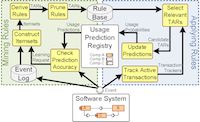
When I was extending the repository of adaptation patterns, I noticed that some styles (such as peer-to-peer) are encoding very limited knowledge. As a result, the adaptation patterns corresponding to those styles were not rich, and in turn, not helpful in reducing disruption. For decreasing disruption in systems with such styles or no style at all, more information is required. I realized that data mining approaches can be applied to these systems to extract the required knowledge. Most systems keep their execution log for an extended period of time to enable auditing. Execution logs usually contain information about the transactions and the times they were running in the system. The result of running data mining algorithms on the execution logs is a set of dependency rules between components. I used these rules at run-time to maintain consistency with limited disruption in the system during changes.
Main Publication
|
|
|
|
|
Savasana
|
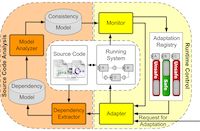
Many existing approaches for safe adaptation require behavioral models of the system. Often such models are either not available (e.g., in open-source software system) or provide an inaccurate representation of the system's evolving dependencies. Serenity deals with these problems by statically analyzing the application logic (i.e., source code) of a component-based software system to derive very detailed models of its behavior. Serenity then uses these models at run-time to ensure the consistency of adaptation. Since Serenity has more information at its disposal, it is able to identify more opportunities for consistent adaptation of software than what is possible with prior techniques. In other words, Serenity is able to enact the changes in the software faster than prior approaches.
Main Publication
|
|
|
|
|
Vulnerability Assessment of Android Applications
|
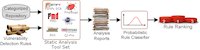
One of the most important quality attributes is security. In fact, security has become the Achilles' heel of most modern software systems. It is very important to detect security problems prior to releasing the software. However, the available techniques for detecting vulnerabilities (e.g., manual inspection and automated analyses) are time consuming and cannot keep up with the exponential growth in software repositories for smart phones. To deal with this problem, I applied data mining on the meta-data embedded in the categories of such repositories to predict the likelihood of presence of a vulnerability in an Android app. Since, smart phone apps are built according to a relatively rigid framework, categories of application could effectively classify vulnerabilities. I was able to prioritize vulnerabilities based on the probability of their presence and improve the efficiency of vulnerability detection.
Main Publication
|
|
|
|
|
Automated Android Security Testing
|
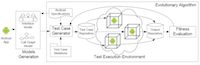
After detecting potential vulnerabilities, it is very important to see if they can be misused during the execution of the application. To that end, I designed a framework that harnesses the unprecedented computational power of cloud computing for testing Android applications. I used a combination of symbolic execution and evolutionary algorithms to find exploitable vulnerabilities in Android applications. In a sense, I devised a scalable approach for intelligent fuzz testing of Android applications, where the scalability is backed by the cloud and intelligence is backed by symbolic execution/evolutionary algorithms. The framework has shown promising results in detecting a large number of exploitable vulnerabilities in Android.
Main Publication
|
|
|
|
|
|
|
Copyright © 2001-2019 Naeem Esfahani | Best View in Mozilla Firefox | Last Update: May 12, 2019
|

