Search engines such as google have to filter through millions of webpages to return relavent webpages based on a search query. The first task it carries out is word matching. This alone will still return a very large amount of webpages unless the search query is very specific. The search engine needs to rank each page based on relevance without getting stuck in a loop. Consider a graph where each of n nodes represents a web page, and a directed edge from node i to node j means that page i contains a web link to page j. (Like the graph below.)
Let A denote the adjacency matrix, an n x n matrix whose ij th entry is 1 if there is a link from node i to node j , and 0 otherwise. For the graph above the adjacency matrix is:

Given the adjacency matrix we can find the probability of being at node j from this formula:
\begin{align*} p_{j}= \sum_{i}\left(\frac{qp_{i}}{n}+\frac{\left(1-q\right)p_{i}A_{ji}}{n_i}\right) \end{align*}which is equivalent in matrix terms to the eigenvalue equation:
where \(p = (p_{i})\) is the vector of n probabilities of being at the n pages, and G is the matrix whose \(ij\) entry is \(q/n + A_{ji}(1 - q)/n_{j}\). We will call G the google matrix.
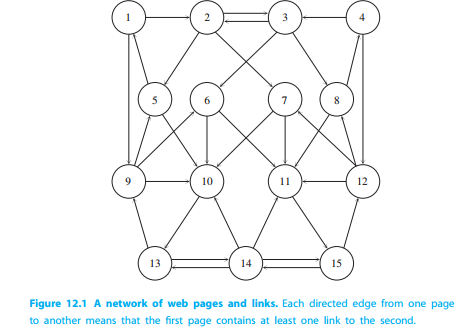
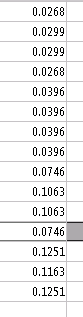
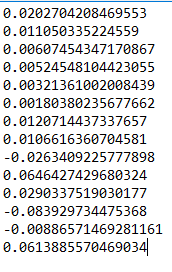
From setting q=0.15 we get the principal eigenvector (corresponding to dominant eigenvalue 1) of the google matrix G is
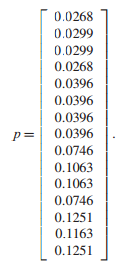
Here we show that the google Matrix is a stochastic matrix. In other words, we show that the sum of the entries in some column \( j \) adds up to one. So here notice that given that \( G_{ij}=\frac{q}{n}+\frac{\left(1-q\right)A_{ji} }{n_j} \), we observe that the formal sum of the entries of some column \(j\) is: \begin{align*} \sum_{i=1}^{n}\frac{q}{n}+\frac{\left(1-q\right)A_{ji}}{n_j} &= \sum_{i=1}^{n}\frac{q}{n}+\frac{\left(1-q\right)A_{ji}}{A_{j1}+A_{j2}+...+A_{jn}}\\ &= n\frac{q}{n}+ \frac{\left( A_{j1}+A_{j2}+...+A_{jn}\right)\left(1-q \right)}{A_{j1}+A_{j2}+...+A_{jn}}\\ &= q + 1-q\\ &= 1 \end{align*}
We were asked to construct the google matrix G and verify the given dominant eigenvector \(p\) for the network above. Our code that allows for any input adjacency matrix A and will give the google matrix G and the dominant eigenvector \(p\):G Matrix Code
Inputing the matrix A above into our code gives us the following G matrix and \(p\) vector:
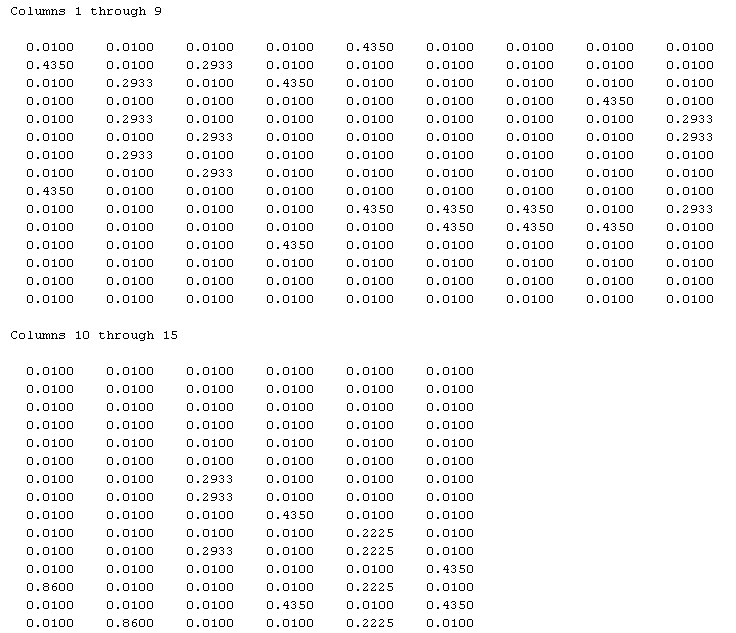
In this part of the project, we were asked to play around with the parameter \(q\), the probability that you will leave the current webpage to go to one of the linked ones. The following \(p\) vectors are the outputs for \(q = 0.15, 0.0, 0.5\) respectively.
Thus, it is clear that when the \(q\) value increases, the probabilities of landing on the respective pages are closer together. However, when \(q\) is made lower than 0.15, the pages with more links see an increased probability of being visited, while the pages with less links see a decreased probability. \(q\) therefore represents the probability that the user will leave the current page for one of the linked pages.
Next, we were supposed to analyze the effects of the following scenario: in an attempt to have a higher page rank than 6, 7 convinces 2 and 12 to more prominently display links to page 7, corresponding to adding 1 to the entries \(A_{2,7}\) and \(A_{12,7}\) in the adjacency matrix. The before and after of this change is reflected in the following \(p\) vectors, with \( q = 0.15\).
Yes, this strategy succeeded for page 7, in there is a noticable difference in the probability of its page being visited, from 0.0396 to 0.0528. Additionally, 6's probability decreased slightly from 0.0396 to 0.0390. Also, all except for 4 other pages' (9, 10, 13, 14) probabilities decrease.
For this part we wanted to see the effects of removing page 10 from our network above. The difference in the output of pages 1-9 and 11-15 are below (with 10 being omitted). The code is here: Part 5 Code
The network that we chose to use was the network of the class web pages for this Math 447 class. We included the 19 pages for each of the students and Dr. Sauer's page that links to all of them. A directed graph depicting the class' network is below.
The adjacency matrix for this network is \[A=\begin{pmatrix} 1 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 1 & 0 \\ 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 1 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 & 0 & 0 & 1 & 0 & 0 & 1 & 0 & 1 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 1 & 1 & 0 & 0 & 1 & 0 & 0 & 1 & 1 & 0 & 0 & 1 & 0 & 0 & 1 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 1 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 1 \\ 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \\ \end{pmatrix} \] We made the adjacency matrix have each website refrence itself to prevent division by zero when the sum of all their links are calculated.
Using the same function from Part 2 the Google Matrix with a 15% probability of going to a random page can be calculated. The Google matrix can be found on this page. The corresponding probability vector for the Google matrix (the normed largest eigenvector) is \[\begin{pmatrix} 0.0131 \\ 0.0722 \\ 0.0358 \\ 0.0183 \\ 0.0182 \\ 0.0188 \\ 0.0183 \\ 0.0722 \\ 0.2332 \\ 0.0263 \\ 0.0337 \\ 0.0223 \\ 0.0722 \\ 0.0263 \\ 0.0722 \\ 0.0870 \\ 0.0189 \\ 0.0298 \\ 0.0327 \\ 0.0784 \\ \end{pmatrix}.\] A table matching the probabilities to the website owner is below.
| Andrada | 0.0131 |
| Argus | 0.0722 |
| Arneja | 0.0358 |
| Bender | 0.0183 |
| Bishop | 0.0182 |
| Bouck | 0.0188 |
| Caetto | 0.0183 |
| Collins | 0.0722 |
| Easley | 0.2332 |
| Jugus | 0.0263 |
| Lasseigne | 0.0337 |
| Lee | 0.0223 |
| Malhotra | 0.0722 |
| Markowski | 0.0263 |
| McLane | 0.0722 |
| McNulty | 0.0870 |
| Reid | 0.0189 |
| Sarkhel | 0.0298 |
| Smith | 0.0327 |
| Sauer | 0.0784 |
When the probability of going to a random page in increased from 15% to 50%, the probabilities for ending on any of the pages are closer to each other. The probabilities when the chance of going to a random page is 50% are
| Andrada | 0.0303 |
| Argus | 0.0545 |
| Arneja | 0.0490 |
| Bender | 0.0357 |
| Bishop | 0.0364 |
| Bouck | 0.0364 |
| Caetto | 0.0357 |
| Collins | 0.0545 |
| Easley | 0.1056 |
| Jugus | 0.0418 |
| Lasseigne | 0.0508 |
| Lee | 0.0400 |
| Malhotra | 0.0545 |
| Markowski | 0.0418 |
| McLane | 0.0545 |
| McNulty | 0.0606 |
| Reid | 0.0348 |
| Sarkhel | 0.0452 |
| Smith | 0.0472 |
| Sauer | 0.0907 |
| Andrada | 0.0055 |
| Argus | 0.0893 |
| Arneja | 0.0186 |
| Bender | 0.0083 |
| Bishop | 0.0081 |
| Bouck | 0.0085 |
| Caetto | 0.0083 |
| Collins | 0.0893 |
| Easley | 0.3411 |
| Jugus | 0.0129 |
| Lasseigne | 0.0166 |
| Lee | 0.0103 |
| Malhotra | 0.0893 |
| Markowski | 0.0129 |
| McLane | 0.0893 |
| McNulty | 0.1103 |
| Reid | 0.0088 |
| Sarkhel | 0.0147 |
| Smith | 0.0165 |
| Sauer | 0.0414 |
When Dr. Sauer's page is removed from the network, the pages that linked to his page usually have their probabilities go up and the ones that did not usually had their probabilities go down. The probabilities from this situaiton are in the table below.
| Andrada | 0.0095117 |
| Argus | 0.0526316 |
| Arneja | 0.1047820 |
| Bender | 0.0169267 |
| Bishop | 0.0165421 |
| Bouck | 0.0526316 |
| Caetto | 0.0135807 |
| Collins | 0.0526316 |
| Easley | 0.2054769 |
| Jugus | 0.0211217 |
| Lasseigne | 0.0317904 |
| Lee | 0.0208258 |
| Malhotra | 0.0526316 |
| Markowski | 0.0263256 |
| McLane | 0.0526316 |
| McNulty | 0.0634115 |
| Reid | 0.0151372 |
| Sarkhel | 0.0919692 |
| Smith | 0.0994407 |
When all the links to Dr. Sauer's page are increased in prominence (have their value in the adjacency matrix doubled), the probabilities become slightly closer together. This is because Dr. Sauer's website has more influence going to it and that influence is spread to the other 19 websites evenly.
| Andrada | 0.013704 |
| Argus | 0.075830 |
| Arneja | 0.029681 |
| Bender | 0.017397 |
| Bishop | 0.017402 |
| Bouck | 0.015871 |
| Caetto | 0.019116 |
| Collins | 0.075830 |
| Easley | 0.226784 |
| Jugus | 0.026722 |
| Lasseigne | 0.032065 |
| Lee | 0.021031 |
| Malhotra | 0.075830 |
| Markowski | 0.024319 |
| McLane | 0.075830 |
| McNulty | 0.091361 |
| Reid | 0.019151 |
| Sarkhel | 0.024186 |
| Smith | 0.026728 |
| Sauer | 0.091163 |
In all cases, the pages with the highest probability of ending on were the pages that had links towards them, but did not have any links away from them. The demonstration of this is that Julian Easley's page had 5 links towards it but no links out, and that page had a higher probability than Dr. Sauer's page which had 6 links to it but 19 out of it.